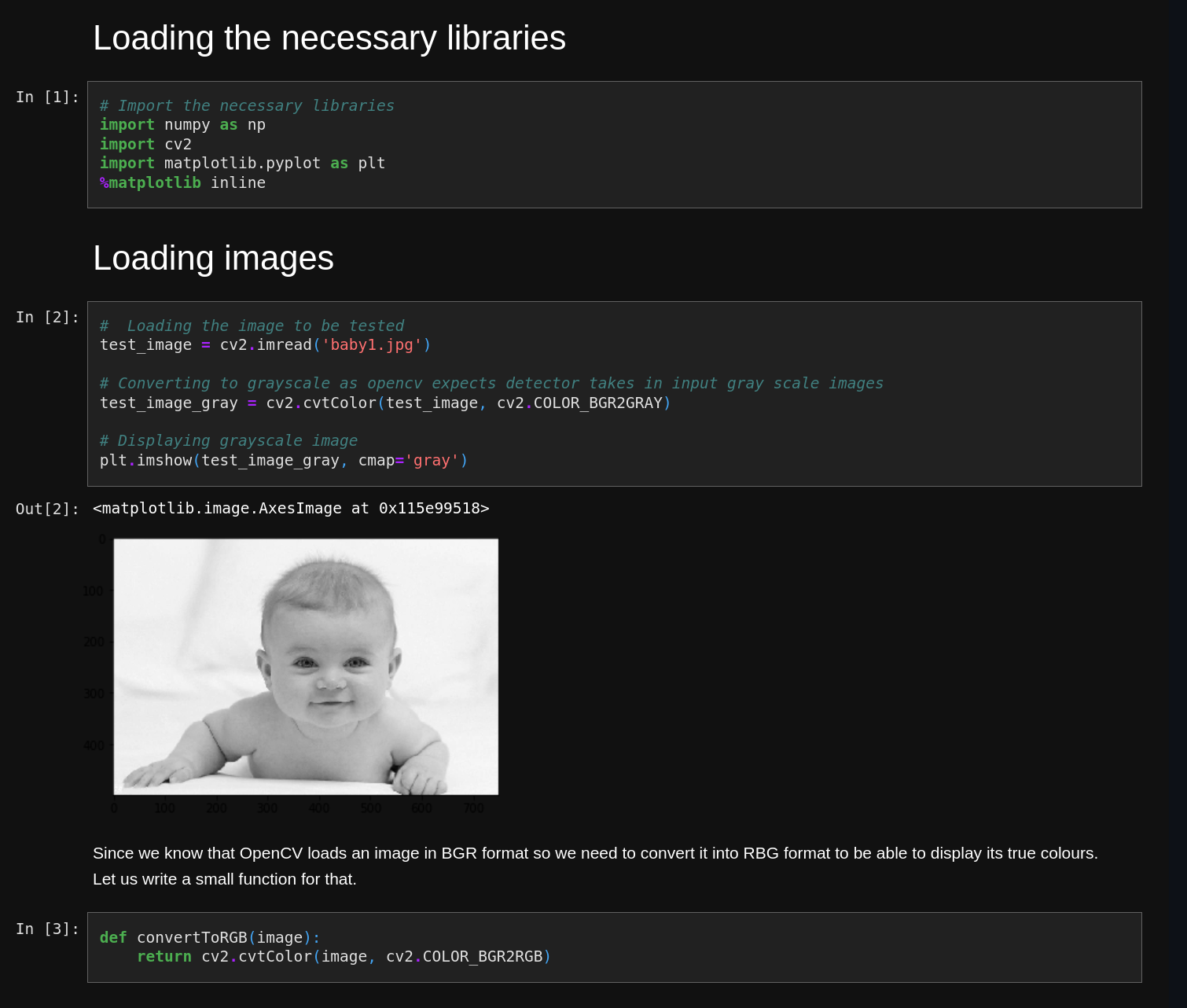
I have a couple old related blog posts here: Continuously Deploying Django with Docker (2015) and Continuously Deploying Django with GitHub Actions (2019). They describe my approach (at the time) to deploying Django apps on a simple cluster of servers, achieving continuous deployment with zero downtime and some basic failover and scalability capabilities.
At the end of the first one, I say:
Nevertheless, what I’ve put together is basically a low rent, probably buggy version of a PaaS. I knew this going in. I did it anyway because I wanted to get a handle on all of this myself. (I’m also weird and enjoy this kind of thing). Now that I feel like I really understand the challenges here, when I get time, I’ll probably convert it all to run on Kubernetes or Mesos or something similar.
And, several years later, I feel like I should probably mention that yes, I did actually just convert it all to run on Kubernetes. That was actually quite a while ago, but I’ve been lazy about blogging.
Since I got a lot of positive feedback on the previous posts, I figure I ought to write up my Kubernetes setup as well in the hopes that people find that useful.
Let’s talk about Kubernetes really quickly first. I should stress that I am, by no means, a Kubernetes expert. I’ve gone through the exercise of setting up and running a cluster manually. As a learning exercise, I highly recommend doing that. If you’re actually going to run a Kubernetes cluster with production workloads I only recommend going that route if you plan to invest a significant amount of time in becoming a Kubernetes expert. Kubernetes has a reputation for complexity and it’s deserved when it comes to building, operating, and maintaining a cluster. Just deploying an application to a Kubernetes cluster that someone else is responsible for operating is actually quite simple though. These days, there are a number of options for managed Kubernetes clusters that you can just pay for. I have experience with GKE and DigitalOcean Managed Kubernetes and can recommend either of those. I’m sure the equivalent offerings from AWS, etc. are also fine; I just don’t have experience with them.
The setup I’ll describe for my personal apps here uses DigitalOcean Kubernetes. I’ll point out a few things that are specific to that, but most of it will be pretty generic.
For the most part, the underlying Django applications are still structured the same and packaged individually as Docker images pretty exactly as described in the previous blog posts. The actual Dockerfiles, python dependencies, etc. have all been updated over the years to more modern approaches, but the end result is still an image that is more or less a black box that takes its configuration from environment variables (à la 12 factor apps. Kubernetes just runs docker containers, so I really didn’t have to change the apps to run them there.
Again, I’ll use my RSS feed reader app, “antisocial”, as the example and go through its configuration. That’s because it has both a web component as well as Celery workers and Celery Beat, which also need to run. That’s the most complicated one I have. Other apps that don’t need Celery or Celery Beat are basically the same, but even simpler than what I’ll show here.
My DigitalOcean Kubernetes cluster is pretty small, just three nodes with enough RAM to handle all the apps I want to run on them. Again, I aim to have at least two instances of the web component running behind a load balancer for basic failover and to allow for zero downtime deployments. With three nodes in my cluster, I want it to be able to keep serving traffic even if it loses one node. If this were for production workloads and not just my personal apps that don’t really need high availability, I’d set up a larger and more redundancy. For my personal apps though, I need to keep the costs reasonable.
The apps all use a shared managed PostgreSQL instance (again, run by DigitalOcean) and serve static files via AWS S3 and CloudFront. So the Kubernetes cluster is just handling the actual Django web apps and Celery workers as well as a RabbitMQ instance that connects them.
Kubernetes has a number of abstractions that we’re going to have to look at. I won’t go into great detail on each, since there are better resources out there for learning Kubernetes. Instead, we’ll just look at how they are set up for this Django app and how they fit together.
Another quick note: Kubernetes has a bunch of features like namespaces and RBAC that let you secure everything and prevent applications running on the same cluster from accessing each other (accidently or maliciously). Since this is all just my personal side project stuff, I’ve skipped as much of that as I can. If you are going to use Kubernetes for production, really need to go learn that stuff and understand it first.
Pretty much everything in Kubernetes is just defined in a YAML file. You then (after setting up some auth stuff that I won’t cover), interact with your cluster by running kubectl apply -f some_file.yaml. Kubernetes reads the defnition of whatever you are creating or updating in that file and updates the cluster to match it. Yes, you quickly get a bit overwhelmed with the amount of YAML involved and how verbose it can be, but you get used to it and the consistency of the interface is pretty nice.
The first thing we need for the app is a Service, which is just an abstraction for an application that will be running and accessible on the internal network. So, we have service.yaml like:
----
apiVersion: v1
kind: Service
metadata:
name: antisocial
labels:
app: antisocial
spec:
type: NodePort
selector:
app: antisocial
ports:
- port: 8000
targetPort: 8000
name: gunicorn
All that’s really doing when we run kubectl apply -f service.yaml is setting up some routing information to let the cluster know that there’s some “antisocial” application that will be exposing “gunicorn” on port 8000. We’re not actually running anything yet.
The next thing we need is configuration for our applications. In my old setup, I could deploy config files and put environment variables into Systemd/upstart configs as needed. Since you don’t typically have access to the servers in a Kubernetes cluster, you need a different approach. Kubernetes provides a ConfigMap abstraction which is just bundle of key/value pairs. We make one for the app in configmap.yaml:
---
apiVersion: v1
kind: ConfigMap
metadata:
name: antisocial-config
data:
DB_HOST: "....db.ondigitalocean.com"
DB_USER: "antisocial"
DB_PORT: "25060"
AWS_S3_CUSTOM_DOMAIN: "....cloudfront.net"
AWS_STORAGE_BUCKET_NAME: "thraxil-antisocial-static-prod"
ALLOWED_HOSTS: ".thraxil.org"
HONEYCOMB_DATASET: "antisocial"
Any other settings that we need could be added there. Again, a simple kubectl apply -f configmap.yaml and it’s built in the cluster.
A bad approach would be to put sensitive data like passwords or the django secret key into the ConfigMap. It would work, but isn’t recommended. Instead, Kubernetes also has Secrets which are very similar to ConfigMaps but, as the name implies, intended for secret and sensitive values. There are a bunch of different ways to set up and manage secrets. The approach I took was to have essentially an .env file called secrets.txt with just key/value pairs for the secrets like:
SECRET_KEY=....
DB_PASSWORD=....
AWS_ACCESS_KEY=...
AWS_SECRET_KEY=...
And so on. Then I do kubectl create secret generic antisocial-config --from-env-file ./secrets.txt to load them into the cluster.
So, we have a Service, and configuration split into the secret and non-secret parts. Now we are ready to actually connect those up and run our application.
Kubernetes does that, along with some more information about the steps involved in spinning up your services in a Deployment. It’s a bit of a weird abstraction at first, but quickly became one of my favorite aspects of Kubernetes once I understood it. The Deployment defines the complete desired state of the application along with enough information for the Kubernetes cluster to figure out how to achieve that desired state no matter what state it starts out in.
Let’s start by just looking at the Deployment for the web app part (ie, gunicorn) without any of the Celery stuff:
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: antisocial-app
labels:
app: antisocial
spec:
replicas: 2
selector:
matchLabels:
app: antisocial
template:
metadata:
labels:
app: antisocial
spec:
affinity:
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: app
operator: In
values:
- antisocial
topologyKey: kubernetes.io/hostname
containers:
- image: <IMAGE>
name: antisocial
envFrom:
- secretRef:
name: antisocial-secret
- configMapRef:
name: antisocial-config
ports:
- containerPort: 8000
name: gunicorn
The last part of that is actually a good place to start. That specifies the container that’s going to run, gives it the name antisocial, sets up an environment from the ConfigMap and Secrets that we defined, and tells Kubernetes that those containers will be exposing port 8000 with the name gunicorn, which lets it associate those container/ports with the abstract Service that was defined way back at the beginning. The -image: <IMAGE> line we’ll come back to later.
The replicas: 2 line tells it to run two instances of this container. Then, the whole podAntiAffinity: block basically tells Kubernetes to do its absolute best to run those two instances on different physical nodes (the underlying servers). Having two instances running doesn’t help us much for failover if they’re running on the same node and that node goes down. “Anti-affinity” is Kubernetes’ way of letting you avoid that, while also letting Kubernetes otherwise have complete control over which containers run on which nodes without you having to micro-manage it.
The other wonderful thing about that config is that by default Kubernetes does a rolling deploy with zero downtime. When a new image gets deployed, it spawns instances of the new version and waits until they’re running before moving traffic over to them and only then shutting down the old ones. If you define health check endpoints in your containers, it will wait until the new ones are actually able to handle traffic. If you want to get really fancy, you can replace the health checks with more complicated checks that, eg, look at external metrics like error rates or latency and you can configure it to roll out the new version in small steps, only continuing if those metrics look good (ie, canary deploys).
The Celery Beat Deployment is very similar:
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: antisocial-beat
labels:
app: antisocial-beat
spec:
replicas: 1
selector:
matchLabels:
app: antisocial-beat
template:
metadata:
labels:
app: antisocial-beat
spec:
containers:
- image: <IMAGE>
name: antisocial
command: [ "/run.sh", "beat" ]
envFrom:
- secretRef:
name: antisocial-secret
- configMapRef:
name: antisocial-config
The differences, aside from it being labeled “antisocial-beat” instead of just “antisocial” are that it only has one replica (you don’t want more than one Celery Beats instance running at once), no ports are exposed, and it adds the command: ["./run.sh", "beat"] parameter which tells the docker container to run the beats service instead of gunicorn.
It’s slightly more complicated with the Celery Workers:
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: antisocial-worker
labels:
app: antisocial-worker
spec:
replicas: 1
selector:
matchLabels:
app: antisocial-worker
template:
metadata:
labels:
app: antisocial-worker
spec:
initContainers:
- image: <IMAGE>
name: migrate
command: [ "/run.sh", "migrate" ]
envFrom:
- secretRef:
name: antisocial-secret
- configMapRef:
name: antisocial-config
- image: <IMAGE>
name: collectstatic
command: [ "/run.sh", "collectstatic" ]
envFrom:
- secretRef:
name: antisocial-secret
- configMapRef:
name: antisocial-config
- image: <IMAGE>
name: compress
command: [ "/run.sh", "compress" ]
envFrom:
- secretRef:
name: antisocial-secret
- configMapRef:
name: antisocial-config
containers:
- image: <IMAGE>
name: antisocial
command: [ "/run.sh", "worker" ]
envFrom:
- secretRef:
name: antisocial-secret
- configMapRef:
name: antisocial-config
It’s basically the same approach as Celery Beat, but adds the whole initContainers block. That defines containers that should be executed once at initialization. In this case, it runs “migrate”, “collectstatic”, and “compress” commands in sequence before starting the Celery worker, which then stays running.
YAML files can be concatenated together into a single file, so all three of those parts go into deployment.yaml. Running kubectl apply -f deployment.yaml will then actually bring everything together and give us a setup with the Celery worker and beats process running, and two gunicorn processes running on different nodes in the cluster. If a node in the cluster goes down, Kubernetes knows what was running on it and will do its best to replicate those containers to other nodes and update the internal network routing to send traffic to them. If containers crash, it will restart them to ensure that the desired number of replicas are always available. If the cluster is expanded, Kubernetes will spread the load out across them as best it can.
Deploying to the cluster is ultimately done by running kubectl apply -f deployment.yaml after updating the -image: <IMAGE> lines in the config to point to a new version of the docker image.
A simple GitHub actions workflow can do that:
on:
push:
branches: master
name: deploy
jobs:
buildDockerImage:
name: Build docker image
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@master
- name: Build docker image
run: docker build -t thraxil/antisocial:${{ github.sha }} .
- name: docker login
run: docker login -u $DOCKER_USERNAME -p $DOCKER_PASSWORD
env:
DOCKER_USERNAME: ${{ secrets.DOCKER_USERNAME }}
DOCKER_PASSWORD: ${{ secrets.DOCKER_PASSWORD }}
- name: docker push
run: docker push thraxil/antisocial:${{ github.sha }}
- name: Update deployment file
run: TAG=$(echo $GITHUB_SHA) && sed -i 's|<IMAGE>|thraxil/antisocial:'${TAG}'|' $GITHUB_WORKSPACE/deploy/deployment.yaml
- name: Install doctl
uses: digitalocean/action-doctl@v2
with:
token: ${{ secrets.DIGITALOCEAN_ACCESS_TOKEN }}
- name: Save DigitalOcean kubeconfig with short-lived credentials
run: doctl kubernetes cluster kubeconfig save --expiry-seconds 600 k8s-1-20-2-do-0-nyc1-....
- name: Deploy to DigitalOcean Kubernetes
run: kubectl apply -f $GITHUB_WORKSPACE/deploy/deployment.yaml
- name: Verify deployment
run: kubectl rollout status deployment/antisocial-app
The beginning of that is the same as before, whenever we merge to master, it builds the docker images (which runs the unit tests), tags it with a git SHA1, and pushes that up to the docker hub. A small extra new step is that it then also does a quick sed to replace all occurrences of <IMAGE> in the deployment.yaml file with the newly created and pushed docker image + tag.
Then it’s a little bit DigitalOcean specific where it authenticates to my cluster.
The actual deploy happens with kubectl apply -f ... deployment.yaml. The next step, kubectl rollout status deployment/antisocial-app isn’t strictly necessary but is a nice feature. That just waits until the cluster reports back that the deployment has succeeded. If the deployment fails for some reason, the GitHub Actions workflow will then be marked as a failure and it’s much more noticable to me.
There’s a final piece that I do need to mention. What’s been covered above gets the application running, but at some point, you need to actually expose it to the rest of the internet on a public interface. Kubernetes refers to this as an Ingress. There are a ton of different ways to do Ingress. It’s common to use Nginx, Traefik, Caddy, HAProxy, or other common reverse proxies or load balancers for ingress, especially if you are running your own cluster. For managed clusters, it’s also common for providers to make their own managed load balancer services available as Kubernetes Ingress. Eg, AWS ELB, GCP HTTPS Load Balancers, etc. Digital Ocean does the same with their load balancer. If you’re using a managed Kubernetes cluster, you probably also want to use the managed load balancer. I’m not going to cover my ingress setup here because it’s specific to the DigitalOcean setup and I will instead just recommend that you follow the instructions for your chosen provider. One nice aspect of pretty much all of them is that they make SSL certificates pretty seamless to manage. If the provider’s ingress doesn’t handle certificates itself, you can use cert-manager with your Ingress. I’ve found it much easier to deal with for Letsencrypt certificates than the standard certbot approach.
Finally, if you’ve read this far, I have a secret for you: I already don’t use this setup. Yeah, by the time I got around to writing up my Kubernetes setup, I’d already moved on to a different approach that I like even better for my personal side projects. I’ll try to be faster about writing about that setup, but no guarantees. In the meantime, I do still recommend a similar approach to Kubernetes, especially if you want that failover and scalability. I’ve barely scratched the surface here of what Kubernetes is capable of as a platform that you can build on. I know it’s an intimidating amount of abstract concepts and YAML when you first encounter it. But compared to a similarly (honestly, much less) capable setup like the previous one I had with VMs running docker and systemd, custom configuration management tools, a consul/etcd cluster, registrator, consul-template, and a bunch of shell scripts for deployment, it really is simpler to deal with. It’s pretty amazing to go into the cluster management console, delete a node, and watch Kubernetes automatically move things around to the remaining servers without dropping any traffic.